3. یک مثال مقدماتی#
3.1. مقدمه#
حال ما آماده ایم تا یادگیری زبان برنامه نویسی پایتون را آغاز کنیم.
در این بخش، ابتدا چند کد کوتاه پایتون می نویسیم و سپس آنها را بررسی و تحلیل می کنیم.
هدف این درس، آشنایی شما با نحو(syntax) پایه ای پایتون و ساختارهای داده ای آن است و با مباحث پیچیده تر در جلسات بعد آشنا خواهیم شد.
پیش از شروع این درس، باید جلسه ی قبل را مطالعه کرده باشید.
3.2. هدف:رسم یک فرآیند نویز سفید#
فرض کنید می خواهیم یک فرآیند نویز سفید به صورت ، شبیه سازی و رسم کنیم، که در آن هر یک مقدار مستقل و از توزیع نرمال استاندارد است.
به بیان دیگر، می خواهیم نمودارهایی همانند نمودار زیر تولید کنیم:
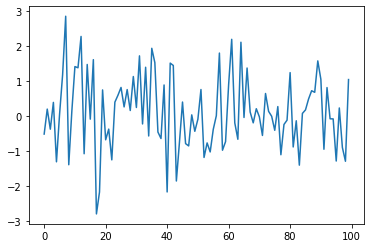
(در اینجا محور افقی و محور عمودی است.)
ما این کار را به چند روش مختلف انجام خواهیم داد و هر بار نکات بیشتری درباره ی پایتون خواهیم آموخت.
3.3. روش اول#
در ادامه چند خط کد آمده که کاری را که تعریف کرده بودیم، انجام می دهد.
import numpy as np
import matplotlib.pyplot as plt
ϵ_values = np.random.randn(100)
plt.plot(ϵ_values)
plt.show()
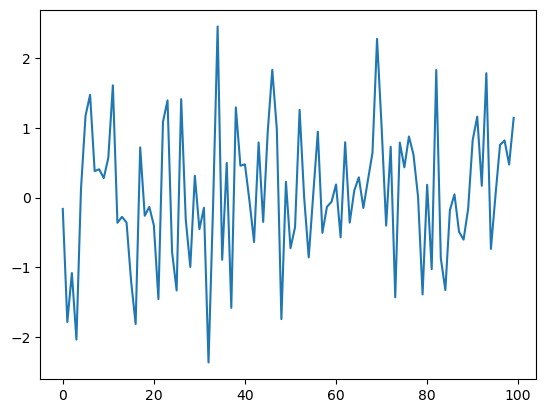
بیایید این برنامه را تجزیه و تحلیل کنیم و ببینیم چگونه کار میکند.
3.3.1. Imports#
دو خط اول کد، قابلیت هایی را از کتابخانه های خارجی وارد می کند.
خط اول NumPY را وارد می کند؛ بسته ای محبوب در پایتون برای کارهایی مانند:
کار با آرایه ها (بردارها و ماتریس ها)
توابع ریاضی رایج مانند
cosوsqrtتولید اعداد تصادفی
جبر خطی و غیره.
پس از وارد کردن کتابخانه با دستور import numpy as np، می توانیم از طریق نحو np.attribute به این قابلیت ها دسترسی پیدا کنیم.
در ادامه دو مثال دیگر آورده ایم:
np.sqrt(4)
np.float64(2.0)
np.log(4)
np.float64(1.3862943611198906)
3.3.1.1. چرا در برنامه نویسی پایتون، از Importهای متعددی استفاده می شود؟#
برنامه های پایتون معمولا به چندین دستور import نیاز دارند.
دلیل این موضوع این است که هسته ی زبانی پایتون عمداً کوچک نگه داشته شده تا یادگیری، نگهداری و توسعه ی آن آسان باشد.
وقتی بخواهید کارهای جالب تر و پیشرفته تری با پایتون انجام دهید، تقریبا همیشه باید قابلیت های اضافی را با استفاده از import به برنامه اضافه کنید.
3.3.1.2. پکیج ها(Packages)#
همانطور که پیشتر گفته شد، NumPy یک پکیج پایتونی است.
پکیج ها ابزاری هستند که توسعه دهندگان برای سازمان دهی کدی که می خواهند به اشتراک بگذارند از آن ها استفاده می کنند.
در واقع، یک پکیج چیزی نیست جز یک پوشه (دایرکتوری) که شامل موارد زیر است:
فایل هایی حاوی کد پایتون - که در اصطلاح پایتون به آن ها ماژول (modules)گفته می شود.
گاهی ممکن است شامل کدهایی کامپایل شده باشد که پایتون توانایی دسترسی به آن ها را دارد (مثلا توابعی که از زبان هایی مثل C یا FORTRAN کامپایل شده اند)
فایلی به نام
__init__.pyکه مشخص می کند هنگامی که می نویسیمimport package_nameچه چیزی اجرا شود
می توانید با اجرای کد زیر در پایتون، محل فایل __init__.py مربوط به NumPY را بررسی کنید:
import numpy as np
print(np.__file__)
3.3.1.3. زیرپکیج ها (Subpackages)#
به خط حاوی ϵ_values = np.random.randn(100) در کد توجه کنید.
در این دستور، np به پکیج NumPY اشاره دارد، و random یک زیرپکیج از NumPY است.
زیرپکیج ها در واقع همان پکیج هایی هستند که به صورت زیرپوشه(ساب دایرکتوری) درون یک پکیج دیگر قرار دارند.
برای مثال اگر به ساختار پکیج NumPY نگاه کنید، می توانید پوشه ای به نام random را درون آن پیدا کنید.
3.3.2. وارد کردن مستقیم توابع یا متغیرها از یک پکیج#
کدی را که پیشتر دیدیم به خاطر بیاورید
import numpy as np
np.sqrt(4)
np.float64(2.0)
در اینجا روش دیگری برای دسترسی به تابع جذر در NumPY آمده است.
from numpy import sqrt
sqrt(4)
np.float64(2.0)
این روش هم کاملا درست کار می کند.
مزیت این روش این است که اگر در کد خود از sqrt زیاد استفاده کنیم، در این صورت تایپ کمتری خواهیم داشت.
اما عیب آن این است که در یک کد طولانی، ممکن است این دو خط با تعداد زیادی از خطوط دیگر از هم جدا شوند.
در این صورت خوانندگان اگر بخواهند بدانند که sqrt از کجا آمده، برای فهمیدن منبع آن دچار مشکل خواهند شد.
3.3.3. نمونه گیری تصادفی#
بیاید به کدی که نویز سفید رسم می کند برگردیم. سه خط بعد از دستور Import به این صورت هستند:
ϵ_values = np.random.randn(100)
plt.plot(ϵ_values)
plt.show()
خط اول 100 عدد نرمال استاندارد (تقریبا) مستقل تولید می کند و آن ها را در متغیر ϵ_values ذخیره می کند.
دو خط بعدی نمودار را رسم می کنند.
در ادامه، روش های مختلفی را بررسی خواهیم کرد تا بتوانیم این نمودار را بهتر تنظیم و بهینه سازی کنیم.
3.4. روش های دیگر پیاده سازی برنامه#
بیایید چندتا نسخه ی جایگزین برای اولین برنامه مان بنویسیم؛ برنامه ای که مقادیر تصادفی مستقل و با توزیع یکسان (IID) از توزیع نرمال استاندارد را رسم می کرد.
برنامه هایی که در ادامه می بینید، نسبت به نسخه اصلی کارایی کمتری دارند و از این نظر کمی غیرطبیعی هستند. اما آنها به ما کمک می کنند تا برخی از سینتکس ها و معانی مهم پایتون را در یک محیط آشنا نشان دهیم.
3.4.1. یک نسخه با حلقه تکرار For#
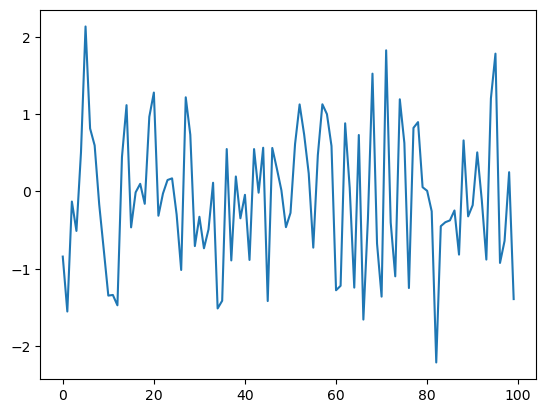
این نسخه حلقه های For و لیست های پایتون را نشان می دهد.
ts_length = 100
ϵ_values = [] # empty list
for i in range(ts_length):
e = np.random.randn()
ϵ_values.append(e)
plt.plot(ϵ_values)
plt.show()
به طور خلاصه:
خط اول طول موردنظر برای سری زمانی را تعیین می کند.
خط بعدی یک لیست خالی به نام
ϵ_valuesایجاد می کند که مقادیر تولید شده را در خود ذخیره خواهد کرد.عبارت
# empty listیک توضیح (کامنت) است و توسط مفسر پایتون نادیده گرفته می شود.سه خط بعدی حلقه
Forهستند که به طور پیوسته یک عدد تصادفی جدید تولید می کنند و آنها را به انتهای لیستϵ_valuesاضافه می کنند.دو خط آخر نمودار را تولید کرده و به کاربر نمایش می دهند.
بیایید برخی از بخش های این کد را با جزئیات بیشتری بررسی کنیم.
3.4.2. لیست ها#
دستور ϵ_values = [] را در نظر بگیرید، این دستور یک لیست خالی ایجاد می کند.
لیست ها یک ساختار داده داخلی در پایتون هستند که برای گروه بندی مجموعه ای از اشیا استفاده می شوند.
همچنین لیست ها ترتیب عناصر را حفظ می کنند و اجازه وجود داده های تکراری را نیز می دهند.
برای مثال، این کد را امتحان کنید:
x = [10, 'foo', False]
type(x)
list
عنصر اول لیست X یک عدد صحیح (integer) است، عنصر بعدی یک رشته متنی (string)، و عنصر سوم یک مقدار بولین (Boolean value) می باشد.
برای اضافه کردن مقدار به لیست میتوانیم از دستور list_name.append(some_value) استفاده کنیم.
x
[10, 'foo', False]
x.append(2.5)
x
[10, 'foo', False, 2.5]
در اینجا ()append یک متد (method) محسوب می شود. متد ها توابعی هستند که به یک شیء متصل می شوند. (در اینجا به لیست X متصل شده است)
ما در ادامه به طور کامل با متدها آشنا خواهیم شد، اما برای درک اولیه:
اشیاء پایتون مانند لیست ها، رشته ها و غیره همگی دارای متد هایی هستند که برای پردازش و تغییر داده های درون شیء استفاده می شوند.
هر نوع شیء در پایتون متدهای مخصوص به خود را دارد، برای مثال اشیاء رشته ای دارای متدهای مخصوص رشته ها هستند ،لیست ها متد لیستی دارند.
یکی دیگر از متدهای کاربردی لیست، ()pop است.
x
[10, 'foo', False, 2.5]
x.pop()
2.5
x
[10, 'foo', False]
در پایتون، شماره گذاری عناصر لیست ها از صفر شروع می شود یا به عبارتی zero-based هستند.(همانند زبان های C، جاوا یا Go) به این معنا که اولین عنصر لیست با x[0] ارجاع داده می شود.
x[0] # first element of x
10
x[1] # second element of x
'foo'
3.4.3. حلقه For#
حالا بیایید حلقه for از برنامه ای که قبلا نوشتیم را دوباره بررسی کنیم:
for i in range(ts_length):
e = np.random.randn()
ϵ_values.append(e)
در اینجا پایتون دو خط تورفته (indented lines) را به تعداد ts_length بار قبل از اینکه به ادامه کد برود، اجرا می کند.
این دو خط به عنوان یک بلوک کد (code block) شناخته می شوند، چرا که “بلوک” کدی را تشکیل می دهد که در حلقه تکرار می شوند.
برخلاف اکثر زبان های برنامه نویسی دیگر، پایتون محدوده بلوک را فقط از روی تو رفتگی تشخصی می دهد.
در برنامه ای که ما نوشته ایم، کاهش تورفتگی پس از خط ϵ_values.append(e) ، به پایتون می فهماند که این خط نشان دهنده انتهای بلوک کد است.
بعدا بیشتر درباره تورفتگی (indentation) صحبت خواهیم کرد؛ اما حالا بیایید به مثال دیگری از حلقه For بپردازیم:
animals = ['dog', 'cat', 'bird']
for animal in animals:
print("The plural of " + animal + " is " + animal + "s")
The plural of dog is dogs
The plural of cat is cats
The plural of bird is birds
این مثال به شفاف سازی نحوه عملکرد حلقه for کمک می کند: هنگامیکه یک حلقه با ساختار زیر اجرا می کنیم
for variable_name in sequence:
<code block>
مفسر پایتون مراحل زیر را انجام می دهد:
برای هر عنصر از دنباله
sequence، نام متغیرvariable_nameرا به آن عنصر متصل (blind) می کند و سپس بلوک کد را اجرا می کند.
3.4.4. یادداشتی درباره تورفتگی (Indentation)#
در بحث درباره حلقه for توضیح دادیم که بلوک های کدی که در حلقه تکرار می شوند با تورفتگی (indentation) مشخص می شوند.
در واقع در پایتون، همه بلوک های کد (شامل آن هایی که درون حلقه ها، شروط if، تعریف توابع و موارد مشابه قرار دارند) با تورفتگی از یکدیگر متمایز می شوند.
برخلاف اکثر زبان های برنامه نویسی دیگر، فاصله های سفید (whitespace) در کد پایتون مستقیما بر خروجی برنامه تاثیر می گذارند.
یکبار که از آن اساده کنید، مزایای کار با آن برایتان آشکار می شود؛ زیرا این قابلیت:
تورفتگی های تمیز و منسجم ایجاد می کند و خوانایی را بهبود می بخشد.
بی نظمی هایی مانند براکت ها یا دستورات پایانی که در زبان های دیگر استفاده می شوند را حذف می کند.
از سوی دیگر، استفاده صحیح از این قابلیت به کمی دقت نیاز دارد، پس بنابراین به یادداشته باشید:
خط ماقبل شروع یک بلوک کد با یک دونقطه (:) پایان می یابد، همانند مثال های زیر :
for i in range(10):if x > y:while x < 100:
همه ی خطوط داخل یک بلوک کد باید مقدار یکسانی تورفتگی داشته باشند.
استاندارد پایتون برای تورفتگی، 4 فاصله (space) است و شما هم باید از همین مقدار استقاده کنید.
3.4.5. حلقه های While#
حلقه for رایج ترین تکنیک برای تکرار در پایتون است.
اما برای توضیح بهتر، اجازه دهید برنامه ای را که قبلا نوشتیم، تغییر دهیم و از یک حلقه while به جای آن استقاده کنیم.
ts_length = 100
ϵ_values = []
i = 0
while i < ts_length:
e = np.random.randn()
ϵ_values.append(e)
i = i + 1
plt.plot(ϵ_values)
plt.show()
حلقه while به اجرای بلوک کد (که با تورفتگی مشخص شده است)ادامه می دهد تا زمانی که شرط (i < ts_length) برقرار باشد.
در این حالت، برنامه به افزودن مقادیر به لیست ϵ_values ادامه می دهد تا زمانی که i برابر با ts_length شود:
i == ts_length #the ending condition for the while loop
True
توجه داشته باشید که:
بلوک کد مربوط به حلقه
whileتنها با تورفتگی (indentation) مشخص می شود.عبارت
i = i + 1را می توان باi += 1جایگزین کرد.
3.5. یک کاربرد دیگر#
بیایید قبل از پرداختن به تمرینات، یک کاربرد دیگر را بررسی کنیم.
در این مثال، موجودی یک حساب بانکی را در طول زمان رسم می کنیم.
در این بازه زمانی هیچ برداشتی انجام نشده و تاریخ پایان دوره را با \(T\) نشان می دهیم.
موجودی اولیه و نرخ بهره \(r\) است.
موجوی حساب از دوره \(t\) به طبق رابطه به روزرسانی می شود.
در کد زیر دنباله ی را تولید و رسم می کنیم.
برای ذخیره این دنباله، به جای استفاده از یک لیست پایتون، از یک آرایه NumPy استفاده خواهیم کرد.
r = 0.025 # interest rate
T = 50 # end date
b = np.empty(T+1) # an empty NumPy array, to store all b_t
b[0] = 10 # initial balance
for t in range(T):
b[t+1] = (1 + r) * b[t]
plt.plot(b, label='bank balance')
plt.legend()
plt.show()
عبارت b = np.empty(T+1) حافظه ای برای ذخیره اعداد T+1 (که اعداد اعشاری هستند) اختصاص می دهد.
سپس این اعداد توسط حلقه ی for مقداردهی می شوند.
اختصاص دادن حافظه در ابتدای کار کارآمدتر از استقاده از یک لیست پایتون و متد append است، چون در روش دوم، برنامه باید به طور مکرر از سیستم عامل درخواست فضای حافظه جدید کند.
توجه کنید که ما به نمودار یک راهنما یا عنوان نمادها (legend) را اضافه کرده ایم ؛ قابلیتی که از شما خواسته خواهد شد در تمرینات استفاده کنید.
3.6. تمرینات#
اکنون به سراغ تمرین ها می رویم. مهم است که آنها را قبل از اینکه به سراغ درس بعدی بروید کامل کنید، زیرا این تمرین ها مفاهیم جدیدی را معرفی می کنند که در ادامه به آن ها نیاز خواهیم داشت.
Exercise 3.1
اولین تکلیف شما شبیه سازی و رسم نمودار یک سری زمانی همبسته (correlated time series ) است.
فرض می شود که دنباله ی شوک ها مستقل و با توزیع یکسان(IID)، و دارای توزیع نرمال استاندارد باشد.
در راه حل خود، دستورات import را تنها به موارد زیر محدود و تنها از کتابخانه های زیر استفاده کنید
import numpy as np
import matplotlib.pyplot as plt
مقادیر \(T\) و \(\alpha\) را به ترتیب \(T=200\) و \(\alpha = 0.9\) قرار دهید.
Solution to Exercise 3.1
یک راه حل این است:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
for t in range(T):
x[t+1] = α * x[t] + np.random.randn()
plt.plot(x)
plt.show()
Exercise 3.2
با استفاده از راه حل تمرین 1، یک سری زمانی شبیه سازی شده رسم کنید؛ یکی برای هر کدام از حالت های \(\alpha=0\)، \(\alpha=0.8\) و \(\alpha=0.98\).
از یک حلقه for برای پیمایش مقادیر مختلف \(\alpha\) استفاده کنید.
اگر میتوانید، یک راهنما(legend) به نمودار اضافه کنید تا بتوان تفاوت بین این سه سری زمانی را تشخیص داد.
Hint
اگر چندبار تابع
plot()را قبل از فراخوانیshow()اجرا کنید، تمام خطوط رسم شده در یک نمودار نمایش داده خواهند شد.برای افزودن راهنما (legend)، توجه داشته باشید که اگر متغیر
var = 42باشد، عبارتf'foo{var}'به رشته'foo42'تبدیل می شود.
Solution to Exercise 3.2
α_values = [0.0, 0.8, 0.98]
T = 200
x = np.empty(T+1)
for α in α_values:
x[0] = 0
for t in range(T):
x[t+1] = α * x[t] + np.random.randn()
plt.plot(x, label=f'$\\alpha = {α}$')
plt.legend()
plt.show()
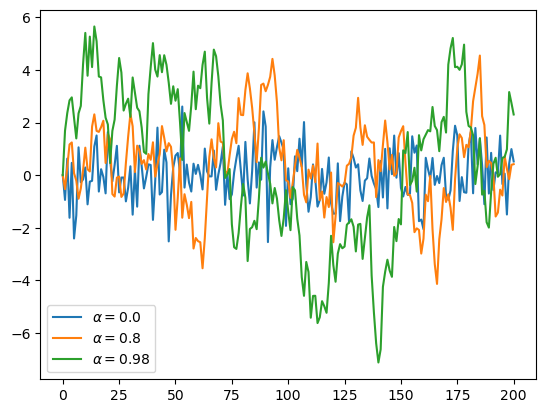
Note
عبارت f'$\\alpha = {α}$' در راه حل، نمونه ای از اف-استرینگ (f-String) در پایتون است. این قابلیت به شما اجازه می دهد تا از {} برای قراردادن یک عبارت درون رشته استفاده کنید.
عبارت داخل {} ارزیابی (محاسبه) می شود و نتیجه ی آن درون رشته جایگزین می گردد.
Exercise 3.3
همانند تمرینات قبلی، سریزمانی را رسم کنید.
همانند قبل از \(T=200\)، \(\alpha = 0.9\) و \(\{\epsilon_t\}\) استفاده کنید.
به صورت آنلاین جست و جو کنید و یک تابع پیدا کنید که بتوان برای محاسبه قدرمطلق از آن استفاده کرد.
Solution to Exercise 3.3
یک راه حل این است:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
for t in range(T):
x[t+1] = α * np.abs(x[t]) + np.random.randn()
plt.plot(x)
plt.show()
Exercise 3.4
یکی از جنبه های مهم، تقریبا در تمام زبان های برنامه نویسی، برنچینگ (branching) و شرط ها (conditions) هستند.
در پایتون، شرط ها معمولا با استفاده از دستور if–else پیاده سازی می شوند.
در اینجا یک مثال آورده شده است که برای هر عدد منفی در یک آرایه مقدار 1- را چاپ می کند و برای هر عدد صفر یا مثبت مقدار 1 را خروجی می دهد:
numbers = [-9, 2.3, -11, 0]
for x in numbers:
if x < 0:
print(-1)
else:
print(1)
-1
1
-1
1
اکنون یک راه حل جدید برای تمرین 3 بنویسید که در آن از هیچ تابع آماده ای برای محاسبه قدرمطلق استفاده نشده باشد.
به جای استفاده از تابع آماده، از یک دستور شرطی if–else برای محاسبه ی قدرمطلق استفاده کنید.
Solution to Exercise 3.4
یک روش این است:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
for t in range(T):
if x[t] < 0:
abs_x = - x[t]
else:
abs_x = x[t]
x[t+1] = α * abs_x + np.random.randn()
plt.plot(x)
plt.show()
در اینجا نیز روش کوتاه تری برای نوشتن همان برنامه وجود دارد:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
for t in range(T):
abs_x = - x[t] if x[t] < 0 else x[t]
x[t+1] = α * abs_x + np.random.randn()
plt.plot(x)
plt.show()
Exercise 3.5
این تمرین کمی سخت تر است و نیاز به فکر و برنامه ریزی دارد.
تکلیف شما این است که با استفاده از روش مونته کارلو، یک تقریب برای عدد محاسبه کنید.
به جز موارد زیر، از هیچ کتابخانه ای استفاده نکنید:
import numpy as np
Hint
راهنماهای شما به شرح زیر است:
اگر \(U\) یک متغیرتصادفی دوبعدی یکنواخت روی مربع واحد باشد، آنگاه احتمال اینکه \(U\) در زیرمجموعه ای \(B\) از قرار گیرد، برابر با مساحت ناحیه ی \(B\) است.
اگر نسخه های مستقل و با توزیع یکسان از \(U\) باشند، آنگاه با بزرگ شدن \(n\)، نسبت نقاطی که در ناحیه \(B\) قرار میگیرند، به احتمال قرارگرفتن در \(B\) همگرا می شوند.
برای یک دایره ، \(مساحت = \pi * شعاع^2\)
Solution to Exercise 3.5
دایره ای با قطر یک را درون یک مربع درنظر بگیرید.
فرض کنید مساحت آن باشد و شعاع آن است.
اگر مقدار را بدانیم، میتوانیم مساحت را از طریق رابطه محاسبه کنیم.
اما در اینجا هدف محاسبه ی است، که میتوانیم از رابطه به دست آوریم.
خلاصه: اگر بتوانیم مساحت دایره ای با قطر 1 را تخمین بزنیم، آنگاه تقسیم کردن آن بر تخمینی برای به ما می دهد.
ما این مساحت را با نمونه گیری از توزیع یکواخت دومتغیره و بررسی کسری از نقاط که درون دایره می افتند، تخمین میزنیم:
n = 1000000 # sample size for Monte Carlo simulation
count = 0
for i in range(n):
# drawing random positions on the square
u, v = np.random.uniform(), np.random.uniform()
# check whether the point falls within the boundary
# of the unit circle centred at (0.5,0.5)
d = np.sqrt((u - 0.5)**2 + (v - 0.5)**2)
# if it falls within the inscribed circle,
# add it to the count
if d < 0.5:
count += 1
area_estimate = count / n
print(area_estimate * 4) # dividing by radius**2
3.14242